Hlavním cílem této studie je vyvinout účinný systém TSDR, který obsahuje obohacený datový soubor malajských dopravních značek. Vyvinutá technika je neměnná v proměnlivém osvětlení, rotaci, translaci a pozorovacím úhlu a má nízkou výpočetní dobu s nízkou četností falešných pozitivních nálezů. Vývoj systému má tři pracovní fáze: předzpracování obrazu, detekci a rozpoznání. Demonstrace systému s použitím segmentace barev RGB a přizpůsobení tvarů následované klasifikátorem podpůrného vektorového stroje (SVM) vedla ke slibným výsledkům s ohledem na přesnost 95.71 %, četnost falešných pozitiv (0.9 %) a dobu zpracování (0.43 s). Oblast pod křivkami provozní charakteristiky přijímače (ROC) byla zavedena pro statistické vyhodnocení rozpoznávacího výkonu. Přesnost vyvinutého systému je poměrně vysoká a výpočetní čas relativně nízký, což bude užitečné pro klasifikaci dopravních značek zejména na dálnicích v Malajsii. Nízká četnost falešně pozitivních výsledků zvýší stabilitu a spolehlivost systému v aplikacích v reálném čase.
1. Úvod
S cílem vyřešit obavy o bezpečnost silničního provozu a dopravy byl zaveden systém automatické detekce a rozpoznávání dopravních značek (TSDR). Automatický systém TSDR dokáže detekovat a rozpoznávat dopravní značky z a uvnitř snímků pořízených kamerami nebo zobrazovacími senzory [1]. Za nepříznivých dopravních podmínek si řidič nemusí všimnout dopravního značení, což může způsobit nehody. V takových scénářích vstupuje do činnosti systém TSDR. Hlavním cílem výzkumu TSDR je zlepšit robustnost a efektivitu systému TSDR. Vyvinout automatický systém TSDR je únavná práce vzhledem k neustálým změnám prostředí a světelných podmínek. Mezi další problémy, které je také třeba řešit, patří částečné zatemnění, zobrazení více dopravních značek najednou a rozmazání a vyblednutí dopravních značek, což může také představovat problém pro účely detekce. Pro aplikaci systému TSDR v prostředí reálného času je zapotřebí rychlý algoritmus. Kromě řešení těchto problémů by systém rozpoznávání měl také zabránit chybnému rozpoznávání neznaček.
Cílem tohoto výzkumu je vyvinout efektivní systém TSDR, který dokáže detekovat a klasifikovat dopravní značky do různých tříd v reálném čase. Pro detekci červených dopravních značek je představena kombinace algoritmu založeného na barvě a tvaru, který upřesní postup fáze detekce a pro rozpoznání jsou zavedeny SVM s obalenými jádry.
Tento příspěvek je uspořádán následovně: Část 2 představuje související práce v oblasti vývoje systému TSDR. V části 3 je diskutována celková metodika. Experimentální výsledky a diskuse jsou shrnuty v části 4. V části 5 jsou uvedeny závěry a některé návrhy pro budoucí zlepšení v oblasti automatické detekce a rozpoznávání dopravních značek.
2. Související práce
Podle [2] byly první práce na automatizované detekci dopravních značek hlášeny v Japonsku v roce 1984. Po tomto pokusu následovalo několik metod představených různými výzkumníky s cílem vyvinout účinný systém TSDR a minimalizovat všechny výše uvedené problémy. Efektivní systém TSDR lze rozdělit do několika fází: předzpracování, detekce, sledování a rozpoznání. Ve fázi předběžného zpracování byl vylepšen vizuální vzhled obrázků. Pro minimalizaci vlivu prostředí na testovací snímky se používají různé přístupy založené na barvě a tvaru [3–6]. Cílem detekce dopravních značek je identifikovat oblast zájmu (ROI), ve které se má dopravní značka nacházet, a ověřit značku po rozsáhlém hledání kandidátů v rámci snímku [7]. K detekci ROI výzkumníci používají různé přístupy založené na barvě a tvaru. Oblíbenými metodami detekce na základě barev jsou transformace HSI/HSV [8, 9], růst oblasti [10], indexování barev [11] a transformace barevného prostoru YCbCr [12]. Protože informace o barvě mohou být nespolehlivé kvůli osvětlení a změnám počasí, je zaveden algoritmus založený na tvaru. Populární přístupy založené na tvaru jsou Houghova transformace [13–15], Detekce podobnosti [16], přizpůsobení transformace vzdálenosti [17] a Hrany s Haarovými prvky [18, 19].
Fáze sledování je nezbytná pro zajištění rozpoznání v reálném čase. Informace poskytované obrázky dopravních značek navíc pomohou ověřit správnou identifikaci a tím detekovat a sledovat objekt [20]. Nejběžněji upraveným sledovačem je Kalmanův filtr [18, 21, 22].
Výzkumníci použili několik metod pro rozpoznání dopravních značek. Ohara a kol. [23] a Torresen a kol. [24] použili techniku Template Matching, což je rychlá a přímočará metoda. Genetický algoritmus používají Aoyagi a Asakura [25] a de la Eccalera et al. [26], který prý není ovlivněn problémem osvětlení. Hlavní výhodou AdaBosst je jeho jednoduchost, výběr funkcí pro velký soubor dat a zobecnění [27]. Li a kol. [28] použili učení Adaboost obsahující pět klasických Haarových vlnek a čtyři funkce HoG (Histogram of Oriented Gradient). Greenhalgh a Mirmehdi [29, 30] ukázali srovnání mezi SVM, MLP, klasifikátory na bázi HOG a rozhodovacími stromy a zjistili, že rozhodovací strom má nejvyšší míru přesnosti a nejnižší výpočetní čas. Jeho přesnost je přibližně 94.2 %, zatímco přesnost SVM je 87.8 % a přesnost MLP je 89.2 %. Neuronová síť je flexibilní, adaptivní a robustní [31]. Hechri a Mtibaa [12] použili 3vrstvou síť MLP, zatímco Sheng et al. [32] použili pro proces rozpoznávání pravděpodobnostní neuronovou síť. Support Vector Machine (SVM) je další populární metodou používanou výzkumníky, která je odolná proti osvětlení a rotaci s velmi vysokou přesností. Yang a kol. [33] a García-Garrido et al. [34] použili k rozpoznání SVM s Gaussovými jádry, zatímco Park a Kim [35] použili pokročilou techniku SVM, která zlepšila výpočetní čas a míru přesnosti pro obrázky ve stupních šedi.
Pro zlepšení míry rozpoznání poškozeného nebo částečně okludovaného znaménka Soheilian et al. v [36] použili porovnávání šablon následované algoritmem 3D rekonstrukce. Zkreslení-invariantní okrajově upravená korelace kloubní transformace (FJTC) byla použita Khanem a kol. v [37] a Principal Component Analysis (PCA) používají Sebanja a Megherbi v [38], které mají velmi vysokou míru přesnosti. V [39] Prieto a Allen použili k rozpoznání samoorganizující se mapu (SOM), jejíž hlavní myšlenkou bylo použít SOM na každé úrovni RS s úspěšností 99 %.
V našem přístupu se pro zkrácení doby zpracování používá k rozpoznání červených dopravních značek segmentace RGB a detekce založená na přizpůsobení tvaru a SVM s obaleným jádrem. Obrázky ve stupních šedi se používají k tomu, aby byl náš detekční a rozpoznávací algoritmus odolnější vůči změnám v osvětlení.
3. Metodika
3.1. Pořízení obrazu
Vzorky se odebírají z levné palubní kamery (Canon SX170 IS), která je připojena k notebooku umístěnému uvnitř vozidla (obrázek 1). Snímky byly pořízeny na různých silnicích a dálnicích v Malajsii za různých povětrnostních podmínek (tabulka 1) od 8:00 ráno. do 8:00 hodin po každých dvou sekundách. Kamera je umístěna na levé straně palubní desky, aby mohla zachytit dopravní značku na levé straně. Cílem této sekce je vytvořit databázi obrázků dopravních značek v různých variantách.
Automatická detekce a rozpoznávání dopravních značek hraje klíčovou roli při řízení inventáře dopravních značek. Poskytuje přesný a včasný způsob správy inventáře dopravních značek s minimálním lidským úsilím. V komunitě počítačového vidění je rozpoznávání a detekce dopravních značek dobře prozkoumaným problémem. Naprostá většina stávajících přístupů funguje dobře na dopravních značkách potřebných pro pokročilé asistenční a autonomní systémy. To však představuje relativně malý počet všech dopravních značek (kolem 50 kategorií z několika stovek) a otevřenou otázkou zůstává výkon na zbývajícím souboru dopravních značek, které jsou nutné k eliminaci manuální práce při řízení inventury dopravních značek. .
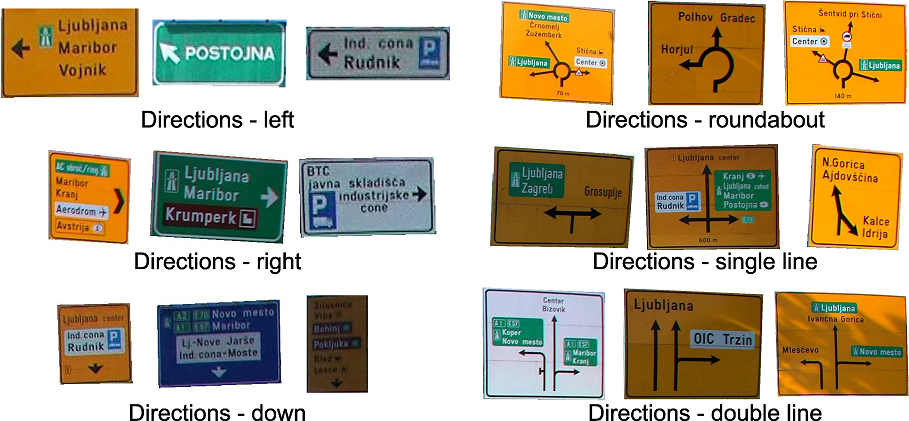
Zabýváme se problematikou detekce a rozpoznávání velkého množství kategorií dopravních značek vhodných pro automatizaci správy inventáře dopravních značek. Přijímáme přístup konvoluční neuronové sítě (CNN), masku R-CNN, abychom se zaměřili na celý kanál detekce a rozpoznávání s automatickým end-to-end učením. Navrhujeme několik vylepšení, která jsou hodnocena při detekci dopravních značek a vedou ke zlepšení celkového výkonu. Tento přístup je aplikován na detekci 200 kategorií dopravních značek zastoupených v našem novém datovém souboru, datovém souboru DFG-TS. Výsledky jsou uvedeny u vysoce náročných kategorií dopravních značek, které dosud nebyly v předchozích dílech zvažovány. S chybovostí pod 3 % je navrhovaný přístup dostatečný pro nasazení v praktických aplikacích řízení inventáře dopravních značek.
Datová sada DFG-TS
Navrhujeme nový náročný soubor dat s 200 kategorií dopravních značek rozprostřeno 13000 XNUMX instancí dopravních značek a 7000 obrázků ve vysokém rozlišení. Soubor dat představuje nový standard pro komplexní úlohu detekce a rozpoznávání dopravních značek s velkým počtem tříd s nízkou variabilitou vzhledu mezi kategoriemi a vysokou variabilitou vzhledu uvnitř kategorií.
Dataset byl vytvořen ve spolupráci se slovinskou společností DFG Consulting d.o.o.
STÁHNĚTE si datovou sadu DFG-TS.

Kód ke stažení
Naše vylepšení masky R-CNN jsou k dispozici v rozvětveném rámci Detectron v našem úložišti GitHub.
výsledky
Na datovém souboru DFG-TS jsou hodnoceny tři nejmodernější detekční modely:
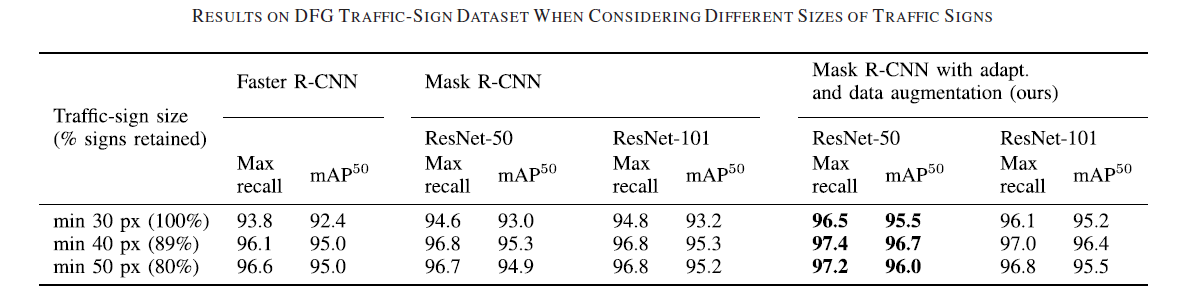
- Rychlejší R-CNN
- Maska R-CNN
- Zakryjte R-CNN našimi vylepšeními
Celkově je přístup založený na hlubokém učení schopen dosáhnout mimořádně dobré výkonnosti pro mnoho kategorií dopravních značek, včetně několika komplexních s velkou variabilitou v rámci třídy. Velká chybovost u problematických kategorií dopravních značek je způsobena většinou podobností s jinými kategoriemi, širokými pozorovacími úhly a velkými okluzemi.
Tyto problémy však nepředstavují problém pro aplikaci vedení přesné evidence inventury dopravních značek. Mohou být zmírněny detekcí přes několik video snímků nebo odpovídajícími 3D umístěními ze stereo kamer. Konkrétně se tento systém již nasazuje pro správu inventáře dopravních značek na slovinských silnicích. Navržené řešení je však aplikovatelné i na další problémy vyžadující schopnost detekce dopravních značek, jako je autonomní řízení a pokročilé asistenční systémy pro řidiče.
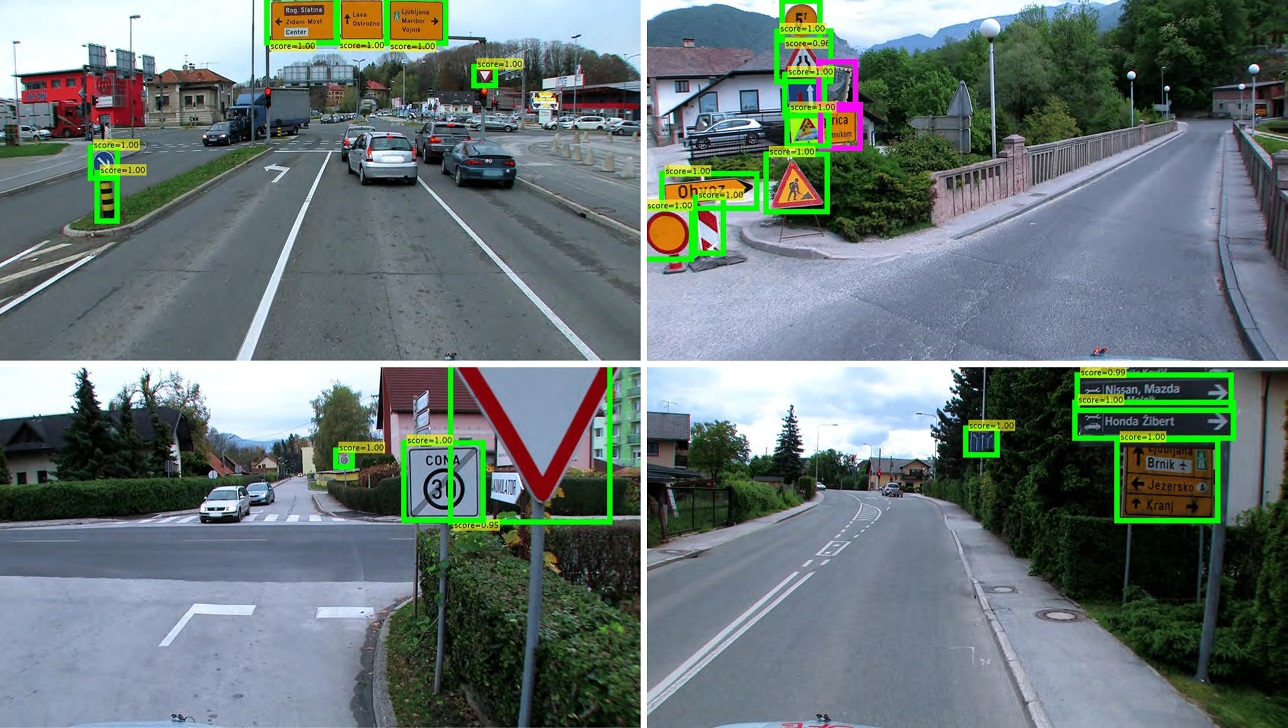
Demonstrace
Pomocí masky R-CNN vyškolené na datové sadě DFG a sledovači LDP v dopředném a zpětném sledování (zpracování offline) běžte v ulicích Lublaně:
















